Anaconda:Python 数据科学的神兵利器
1. 什么是 Anaconda?
简单来说,如果你需要在 Python 中进行科学计算(如使用 NumPy, PyTorch, TensorFlow),Anaconda 是最省心的环境管理和包管理工具。
定义:Anaconda 本质上是一个面向数据科学、机器学习和科学计算的开源发行版。它以 Conda 为核心,预装了 Python 解释器及众多常用的科学计算包,旨在解决环境配置困难、依赖冲突繁杂等痛点。
2. 为什么需要 Anaconda?
在早期或纯 Python 环境下,进行科学计算开发常面临“三大难题”:
- 编译的噩梦:科学计算库(如 NumPy, SciPy)底层大量使用 C/C++ 和 Fortran。使用
pip从源码安装时,往往需要复杂的编译环境(gcc, gfortran 等),一旦缺失便会报错。 - 非 Python 依赖管理:
pip主要是 Python 的包管理器,难以管理非 Python 的库(如 CUDA, HDF5, MKL 等系统级依赖)。 - 环境隔离与依赖冲突:不同项目往往需要不同版本的库。虽然 Python 有
venv,但在处理复杂的科学计算依赖树时,往往力不从心。
Anaconda 的解决方案:
- 预编译二进制包:直接分发编译好的二进制文件(Binaries),无需本地编译,开箱即用。
- 跨语言包管理:Conda 不仅管理 Python 包,还能管理 C/C++, R 等语言的依赖。
- 环境隔离:提供强大的环境管理功能,轻松创建独立的虚拟环境。
3. Anaconda 生态矩阵
很多人容易混淆 Anaconda、Conda、Miniconda 等概念,这里理清一下:
3.1 核心工具
- Conda:核心的命令行工具。它是跨平台(Windows, macOS, Linux)、跨语言的包管理器和环境管理器。
3.2 发行版
- Anaconda Distribution:官方“全家桶”。包含 Conda、Python 以及 700+ 预装的科学计算包。优点是省心,缺点是体积巨大(几 GB)。
- Miniconda:官方“精简版”。只包含 Conda、Python 和基础依赖。按需安装,体积小。
- Miniforge:社区驱动版。类似于 Miniconda,但默认配置为 conda-forge 通道(社区维护的包仓库),且不仅对个人免费,对商业使用也更加友好(规避了 Anaconda 官方频道的商业授权限制)。
3.3 加速与增强
- Mamba:Conda 的 C++ 重写版。极大地提升了依赖解析(Solver)的速度,解决了 Conda 在复杂环境中“解析慢”的老大难问题。
- Channel(通道):相当于软件源。
defaults:Anaconda 官方维护,稳定但更新稍慢,商业使用需付费。conda-forge:社区维护,更新快,包全,免费。
4. 选型对比:Conda vs pip vs uv
| 特性 | pip + venv | Conda / Mamba | UV (Rust based) |
|---|---|---|---|
| 定位 | Python 原生标准 | 跨语言科学计算全能 | 新一代极速 Python 工具 |
| 速度 | 一般 | 慢 (Conda) / 快 (Mamba) | 极快 |
| 依赖处理 | 主要处理 Python 包 | Python + 系统库 (C/C++, R) | 目前主要是 Python |
| 二进制支持 | 依赖 Wheel,部分需编译 | 优秀 (预编译库丰富) | 兼容 pip Wheel |
| 适用场景 | Web 开发、轻量脚本 | 数据科学、AI、复杂环境 | Web 开发、追求极致速度 |
| 缺点 | 科学计算环境配置繁琐 | 体积大、解析慢 (Conda) | 生态相对较新 |
5. 安装与配置
推荐方案:Miniforge (轻量、免费、速度快)。
5.1 安装 (macOS 示例)
使用 Homebrew 安装:
|
|
安装后需初始化 shell(通常安装程序会自动完成,若未完成可执行 conda init zsh)。
5.2 配置国内镜像源
为了加速下载,建议配置清华大学或阿里云镜像。
方法一:命令行配置
|
|
方法二:直接编辑 ~/.condarc
|
|
6. 常用命令速查
环境管理
|
|
包管理
|
|
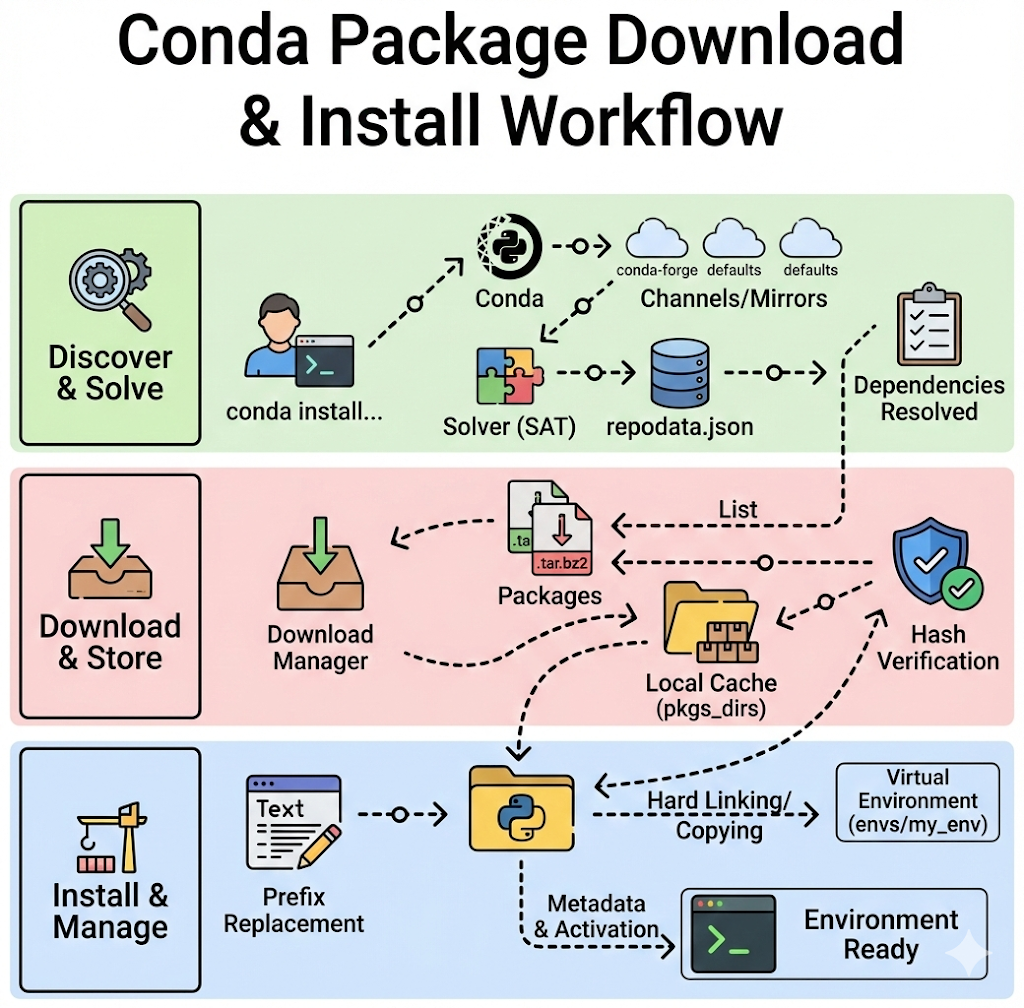
7. 工作原理:conda install 发生了什么?
当你运行 conda install numpy 时,Conda 会经历以下关键步骤:
-
获取元数据 (Fetch Metadata)
- Conda 读取配置文件 (
.condarc) 确定 Channel。 - 下载或更新各 Channel 的索引文件 (
repodata.json),其中包含所有包的版本、依赖关系和构建信息。
- Conda 读取配置文件 (
-
依赖求解 (Dependency Solving)
- Conda 使用 SAT求解器 (Satisfiability Solver) 分析当前环境和目标包的依赖树。
- 计算出一个满足所有版本限制的安装/升级/降级方案。这是 Conda 最耗时的步骤 (Mamba 对此进行了极大优化)。
-
下载与解压 (Download & Extract)
- 下载对应的二进制包 (通常是
.tar.bz2或.conda格式)。 - 校验哈希值,确保存储库安全。
- 将包解压到 Conda 的全局包缓存目录 (
pkgs/)。
- 下载对应的二进制包 (通常是
-
链接 (Linking)
- 硬链接 (Hard Links):Conda 不会将包直接复制到你的虚拟环境中,而是从缓存目录创建“硬链接”到虚拟环境目录。这使得不同环境复用同一个包文件,极大地节省了磁盘空间。
-
前缀替换 (Prefix Replacement)
- Conda 的包是预编译的二进制文件,其中的路径(如 Shebang、RPATH)在编译时是写死的。
- 在安装到新环境时,Conda 会扫描二进制文件中的特定占位符,将其替换为当前虚拟环境的安装路径 (Prefix)。这使得二进制包可以“可重定位” (Relocatable)。